A custom-built experimental setup to study how humans localize sounds in space
Motivation#
To study how humans localize sounds, we have to be able to present sounds from various sources across space. Ideally, there should be no echoes as if one was standing in an open field. To meet these requirements we built a three-dimensional loudspeaker array in a sound attenuated chamber and wrote custom software to present sounds across space with millisecond precision.
Design#
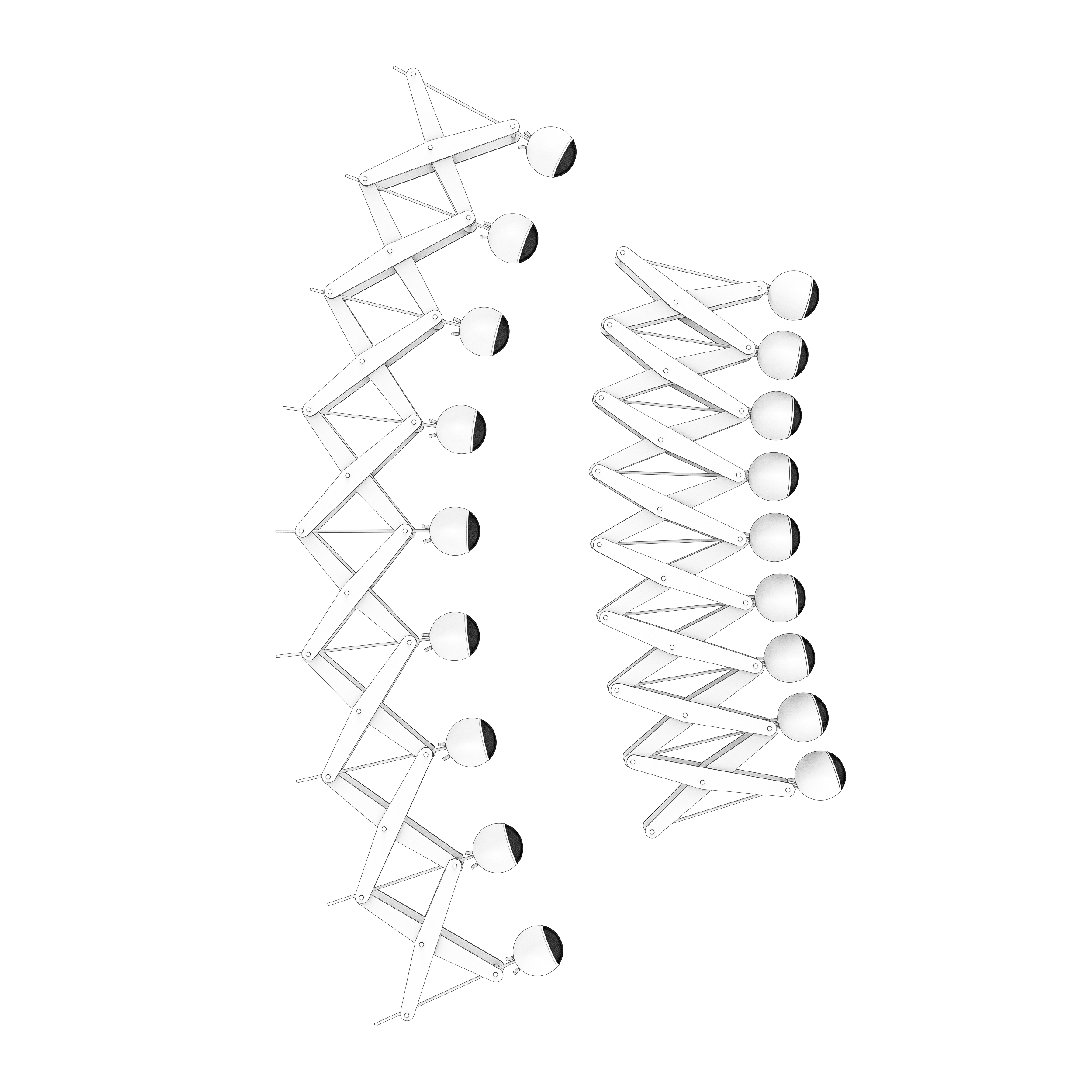
The setup consists of 48 spherical loudspeakers that are mounted on 7 hanging arches. The arches are oriented in parallel to each other and positioned on slices of an imaginary sphere that surrounds the listener. Because they sit on sphere, all loudspeakers have the same distance to the listener.

The individual arches are mobile which allows us to assemble them in various configurations. They can be folded so that as the distance of the listener to the speakers changes, the imaginary sphere shrinks or expands and the vertical and horizontal angles between speakers (alpha and beta in the image above) stay constant.
We wanted to make sure that there are no substantial differences between the transfer functions of individual loudspeakers that could potentially bias experiments. Thus, we contacted the manufacturer to request loudspeakers that were produced in the same batch, to minimize variability. Additionally, we measured each speakers transfer function and computed filters to equalize them. 1
We also mounted three small cameras on the arches in between the loudspeakers. The cameras take pictures of the listener to estimate their head pose so the listeners can localize sounds by turning their heads 2. Because the pose from each camera is in a different camera-centered reference frame, we calibrate the setup by having the participants face several predefined locations. The cameras are sensitive to infrared which allows us to take pictures even when the room is darkened.
Software#
The loudspeakers are driven by two digital signal processors allowing us to display sounds with milliseconds accuracy. However, they are controlled by the manufacturer’s proprietary software that can be configured via a visual interface and is very opaque and difficult to debug. Fortunately, they provide a Python API for setting parameters, playing and recording sounds. We are using a predefined set of simple programs for handling basic operations (like reading a sound into memory and playing it from a specific channel) and use a custom Python toolbox for all remaining tasks. This toolbox also controls the cameras and thus provides a single interface for running experiments. 3