Images-based headpose estimation with convolutional networks and OpenCV
Motivation#
For our experimental setup for studying sound localization 1, we wanted a way to determine a participants head pose from images. That way, we could instruct them to localize sounds by simply looking towards them. Other labs use magnetic trackers for this purpose but we were afraid that their signal might interfere with simultaneous neural recordings.
There exist some ready-made solutions for video tracking using openCV. However, because we only needed the participants head pose at very specific moments, pose-estimation from single images was more appropriate
Design#
The headpose package has one simple purpose: return the head-pose as spherical coordinates (pitch, roll and yawn) from a single image.
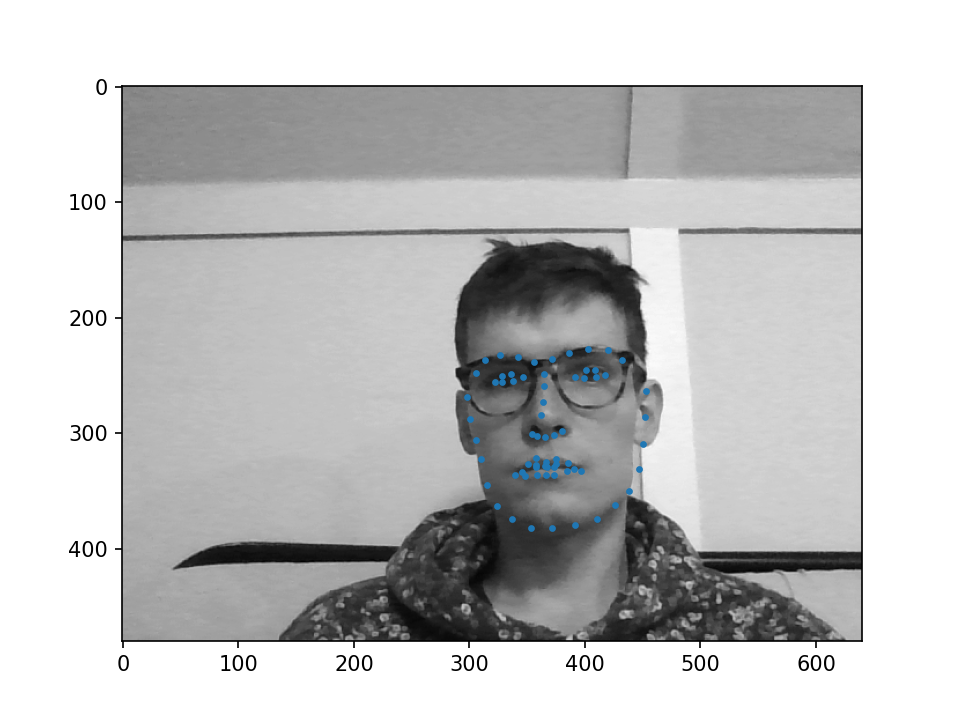
Because the default algorithms provided by OpenCV performed poorly under the bad lighting in our sound-attenuated chamber, I used a convolutional network to detect facial landmark features in the image 2.
From the annotated facial landmarks, a few are selected to solve the perspective-n-problem using a standardized head-model 3. This yields a rotation matrix from which we can extract the desired angles: pitch, roll and yawn.
Example#
Headpose estimation works on any image that contains a single face. We can either download an image with a face or use OpenCV to take an image with a webcam:
import cv2
# take an image using the webcam (alternatively, you could load an image)
cam = cv2.VideoCapture(0)
for i in range(cv2.CAP_PROP_FRAME_COUNT):
cam.grab()
ret, image = cam.retrieve()
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
cam.release()
Then we can use headpose to obtain the pitch, roll and yawn 4 of the face in the image.
By setting plot=True, the acquired image and detected landmark points are shown.
from headpose.detect import PoseEstimator
est = PoseEstimator() #load the model
est.detect_landmarks(image, plot=True) # plot the result of landmark detection
roll, pitch, yawn = est.pose_from_image(image) # estimate the head pose
Resources#
Headpose can be installed along with it’s dependencies from PyPI:
pip install headpose
The code can also be found on GitHub
Footnotes#
This setup is described in detail in another blog post ↩︎
Now OpenCV has built-in functions to use convolutional networks for landmark detection but it didn’t at the time. ↩︎
The perspective-n-problem results from mapping a two-dimensional image to a three dimensional model. The mathematical background is nicely explained in this blogpost ↩︎
Note that the pose is realtive to the camera. Getting the pose with respect to some external coordinate frame requires calibration. ↩︎